Hadoop can be downloaded from the Apache Hadoop website at hadoop.apache.org. This would include core modules like Hadoop Common, Hadoop Distributed File System (HDFS), Hadoop YARN, and Hadoop MapReduce. Additional Hadoop-related projects like Hive, Pig, Hbase and many more can be downloaded from their respective Apache websites. But setting up and doing all this work is not easy.
Once this is done, doing the data-integration is another challenge.
Writing each and everything for the data-integration directly with the pig or hive or other script is bit difficult route to do the required work.
Instead of worrying and doing too much, I think easier way would be to use the sandbox provided by any of hadoop vendor and use the data integration platform by talend. Good thing is this that both hadoop installation and talend big data integration studio software is free and available under apache license :-)
Some of the hadoop vendors are HortonWorks, Cloudera, MapR, etc.
When I first tried the HortonWorks with talend big data integration platform, it made things very easy.
Of-course for enterprise or cloud there is license. But as I mentioned eaerlier, these are available under apache license and free.
So thought of describing how this can be done. In the later post I can explain how talend and hortonworks can be used for their different features. So this post is kind of overview and later post can be in detail for different features.
So what all we need.
1) Virtual machine where hadoop can be installed.
2) Hadoop applicance to be installed on virtual machine, i.e. HortonWorks sandbox.
3) Talend Open Studio for Big Data
4) Create a job for data load on HDFS.
1) Virtual Machine:
I have use oracle virtual box from https://www.virtualbox.org. There was an issue with 4.3 latest version so i used 4.3.12 from the link: https://www.virtualbox.org/wiki/Download_Old_Builds_4_3
One you are finished with installation of virtual box, proceed for next step.
2) Hadoop applicance to be installed on virtual machine, i.e. HortonWorks sandbox:
a) Download:
There are multiple sandbox available from HortonWorks for virtualbox, vmvare, Hyper-v. As we have
installed virtualbox, download that one. It can be donwloaded from the following link:
http://hortonworks.com/products/hortonworks-sandbox/#install
b) Setup:
Start virtualbox, Go to file menu and click on Import Alliance.

Fig: Importing of HortonWorks hadoop appliance-1.
select the appropriate memory and other parameters based on your need. You can set the network

Fig: Importing of HortonWorks hadoop appliance-2.

Fig: Setting of the Network Adapter.
c) Verify - You can verify your installation and find the IP of VM running hadoop.
- Click on the HortonWorks sandbox and click on start button. It will take some time to boot start all services of hadoop, pig, hive, etc and will prompt for authetication.
- Username is "root" and password is "hadoop".
- On the command prompt type ifconfig (as its linux) and note down the ip which would be used in talend studio during the HDFSConnection creation.
- You can use the IP with Port 8000 (default) to check about the successful installation and running of services.
You can browse the various services at : http://xxx.yyy.xxx.zzz:8000/

Fig: Accessing hadoop services using the browser from remote machine.
You can execute some script or browse the older scripts from the pig menu.

3) Talend open studio:
You can download the talend open studio for big data (not the data integration ) from the following link:
http://www.talend.com/download?qt-download_landing=0#quicktabs-download_landing
If you want you can download Talend Big Data Sandbox for any of the hadoop provider but as i wanted to keep these two on separate machine which would be the ideal case.
It would be an .exe file if you are installation on windows, execute it and select the installation location and you are done with the talend open studio installation.
4) Create a job for data load on HDFS:
What we want to do here is to create a job which generate few records and write it to HDFS on the hadoop we have installed in the step 2. Createing and running the job is happening on my local box and hadoop is running on some remote machine.
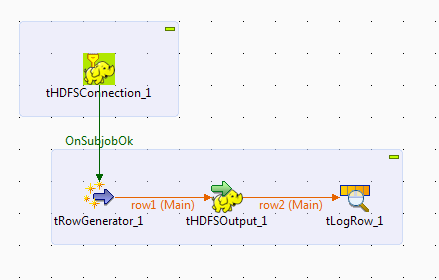
At the end it would look like following and execution of the job would create a file of 100 records in HDFS of hadoop.
a) Start talend by starting TOS_BD-win-x86_64.exe
b) Create a new project and open it.
c) Design a job: Following steps would make job designing complete.
i)) Create a new job by right click on the Repository->Job Design

Fig: Create a new job
ii) Create a new HDFSConnection to connect the the HDFS. As this is going to connect to the sandbox which we have installed earlier, provide the IP and Port (8020) for NameNode URI.

Fig: Create a HDFS Connection and set the URI to the sandbox IP and Port (8020)
iii) Create a tRowGenerator object which would generate the required rows based on the schema created for it. For this example i have created 100 rows. Other information about the schema is available the below images.

Fig: tRowGenerator which would generate 100 rows data.

Fig: Schema for the data generation
iv) Link tHDFSConnection to tRowGenerator: Right click on the tHDFSConnection_1 and click on trigger-> On subjob ok and connect to tRowGenerator_1. This would move start the generator work after connection is successful.
v) Write data to HDFS using tHDFSOutput. Right click on the tRowGenerator_1 and drag it to tHDFSOutput_1. If you need to see the generated output, you can add tLogRow_1 and connect this also in the similar way.

Fig: tHDFSOutput object to write to
Now our design is complete, save it.
d) Run/Execute job to create the file in HDFS. You can either click on the F6 or Run the job by going the Run tab and click on Run button. On Successful execution you would see the filter with the mygeneratedout.csv in the location provided in tHDFSOutput_1, which is "/user/hue/mygeneratedout.csv"

Thanks for reading the blog. :-)
Soon would be write few more blogs on Hadoop and Talend which explains their specific feature in more details.



Deepak....Thanks a lot for the information, It is very helpful for me.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDelete